Introduction
AI Agents are moving beyond chat windows and into enterprise systems, calling APIs, pulling logs, analyzing files, and pushing investigations forward on their own. For security teams, this promises less manual triage and faster outcomes. But enterprise environments don't tolerate unchecked freedom. These systems handle customer data, privileged identities, and production infrastructure where every action must be explainable. When agents dynamically decide how to use tools and traverse systems, that variability becomes part of your risk surface. More capability can mean more attack surface. In this article, we will examine why unbounded autonomy typified by the OpenClaw personal agent framework creates that risk and how structured autonomy delivers machine-scale investigation speed without sacrificing control, governance, or auditability.
Why Does Unlimited AI Agent Autonomy Create Both Promise and Problem?
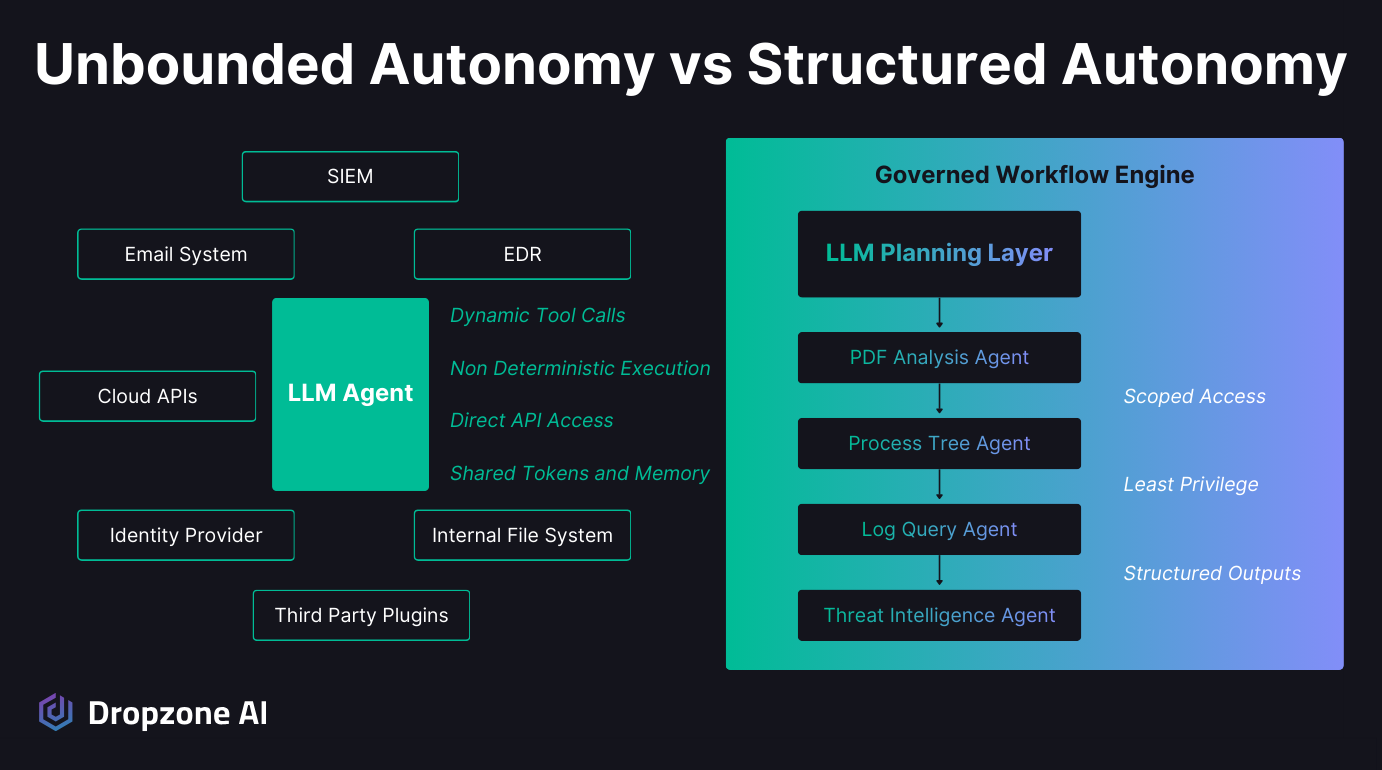
Unlimited autonomy such as that promised by OpenClaw is attractive because it collapses fragmented security workflows into one reasoning system, but that same freedom introduces non-deterministic behavior, broad system access, and new prompt injection risks. The upside is speed and automation; the downside is an expanded attack surface.
Why Does Everyone Want an Agent That Can Do Everything?
OpenClaw made it easy to see the promise of a single agent that can call APIs, access tools, and take action without waiting for human routing. It promised one system that can reason about the situation and decide what to do next. For security teams dealing with alert volume and tool sprawl, that future feels like a clean upgrade.
Dynamic reasoning makes it even more attractive that an agent can adapt investigation paths in real time, pivot across systems, and move from signal to conclusion without rigid branching logic.
That reduces the operational overhead of maintaining fragile automation and speeds up end-to-end execution across multiple platforms. It creates the impression that fragmented workflows can be replaced with a unified digital operator that simply handles the work.
When Does Freedom Become the Attack Surface?
The same flexibility that makes unbounded agents like OpenClaw powerful also makes them difficult to control. Non-deterministic execution paths mean the agent may take different steps each time it encounters similar input.
That variability makes it harder to test, validate, and formally review behavior. In a security environment where reproducibility and auditability matter, unpredictable tool usage poses a risk.
Prompt injection compounds the issue. If an agent can dynamically invoke tools based on model reasoning, manipulated input can redirect that behavior in unintended ways. Three exposure paths widen the blast radius:
- Inherited plugin permissions. Third-party skills or plugins often carry the agent's access to internal systems, expanding exposure beyond the original scope.
- High-value artifacts. Stored tokens, memory artifacts, and configuration files become targets because they hold the context and credentials the agent relies on to operate.
- Regulated-environment visibility. In production, agents may have access to customer data, privileged service accounts, and connectivity to internal APIs and production infrastructure.
Without defined boundaries, every new capability increases the attack surface and potential blast radius. The reasoning layer itself becomes a potential entry point, not because it is malicious, but because it provides attackers with more opportunities for injection or other routes of compromise.
Why Are Guardrails the Real Control System for AI Agents?
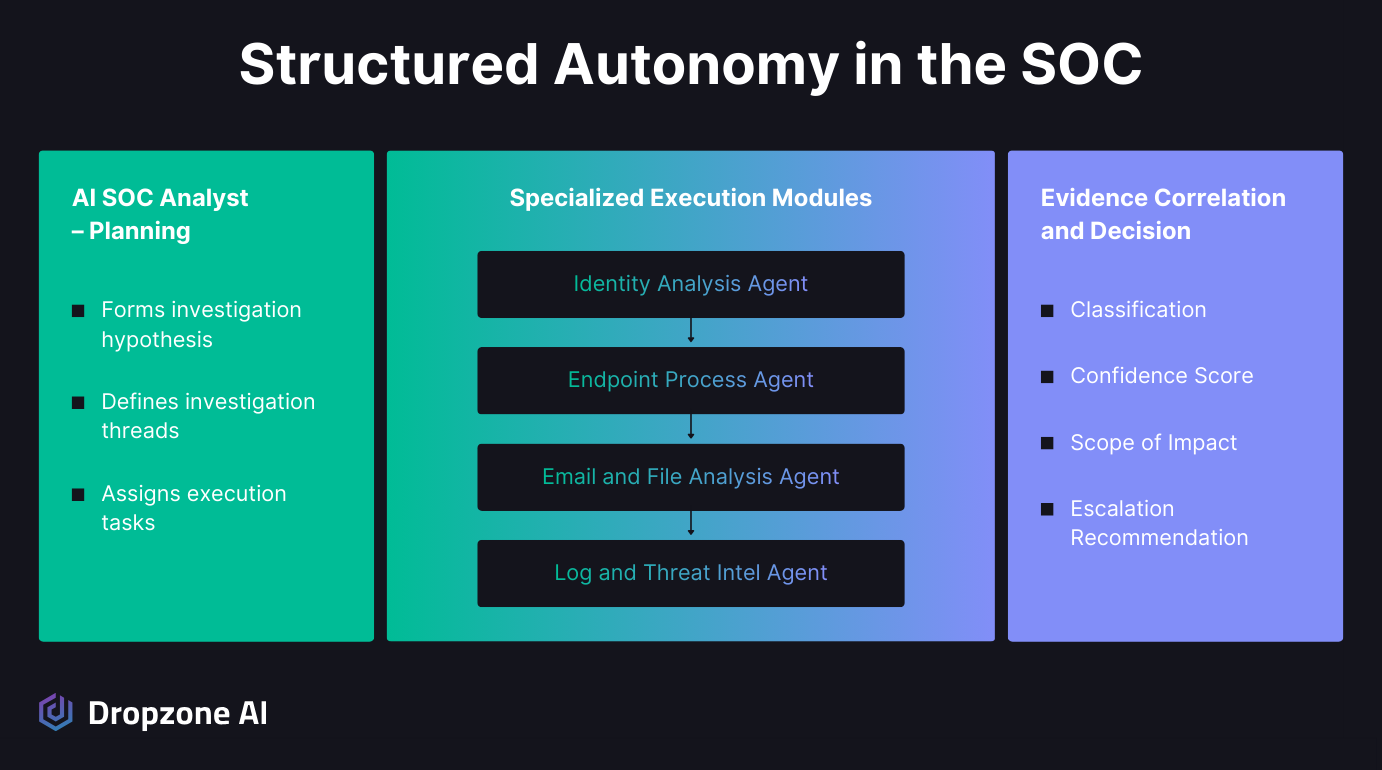
Structure is the control system because it converts unpredictable model behavior into defined workflows, logged actions, and reproducible outcomes. When autonomy follows known inputs, outputs, and validation checks, governance is built into execution rather than patched on after an incident.
How Do Guardrails Make AI Agent Autonomy Safer?
When investigations follow defined workflows, autonomy becomes predictable. Structured autonomy adds four properties that open-ended agents can't offer:
- Clear investigation shape. Each investigation has a defined entry point, explicit exit conditions, and structured steps in between. For example, the Dropzone AI SOC Analyst uses the OSCAR investigative methodology to structure its investigations.
- Typed inputs and outputs. Every step expects specific inputs, produces known outputs, and passes through validation checks.
- Pre-production review and production monitoring. Teams can version the logic, test it in staging, and audit it before it ever reaches production. Performance is monitored in production with quality assurance processes.
- Logged execution and predefined escalation. Every tool invocation and decision branch is logged and inspected, and escalation thresholds are set in advance rather than invented on the fly.
Governance is embedded in execution itself, not layered on after something goes wrong. The system behaves in ways that can be understood, reproduced, and reviewed.
Where Should the LLM Add Judgment and Where Should It Not?
Large language models are powerful when ambiguity is present. They excel at four judgment tasks that are hard to encode as static rules:
- Hypothesis formulation. Reasoning about likely scenarios from incomplete or noisy signals and proposing structured paths to test them.
- Investigation branching. Decomposing a hypothesis into parallel threads such as identity activity, endpoint behavior, and network signals.
- Context synthesis. Pulling evidence from multiple sources into a single picture of what's happening.
- Evidence weighing. Highlighting where evidence disagrees and weighing competing explanations.
Where LLMs should not operate freely is at the infrastructure layer. Specifically:
- Raw-file execution introduces risk when driven directly by dynamic reasoning and without sandbox infrastructure.
- Unbounded system queries widen exposure across privileged data paths.
- Arbitrary API manipulation turns model output into production action without deterministic checks.
Those actions require tightly scoped permissions and deterministic controls. A safer architecture separates planning from execution. The LLM generates the investigative plan and defines what questions need answering. Specialized sub-agents then execute narrowly scoped tasks with least-privilege access.
Sensitive operations run through deterministic logic, not open-ended prompts. Autonomy is concentrated at decision points where judgment is needed, executing human-defined strategy at machine scale, not at the layers that hold credentials, data, and infrastructure access.
What Does Safe AI Agent Autonomy Look Like in a SOC?
Safe autonomy in a SOC separates the LLM's planning role from specialist sub-agents that execute with least-privilege access, log every action, and return structured evidence for human review. Under the agentic SOC model, judgment lives with the model and access lives with the scoped agents.
How Should the LLM Plan While Specialists Execute?
Under the agentic SOC model, the AI SOC analyst starts with a security alert and forms a working hypothesis about what might be happening. It breaks the investigation into clear threads such as identity activity, endpoint behavior, process execution, and network signals. Instead of jumping directly into tool access, it defines what questions need answers and what evidence would confirm or refute the hypothesis.
Execution is then handed to purpose-built sub-agents with narrowly scoped responsibilities. One agent can safely detonate or statically analyze a PDF attachment.
Another can parse and reconstruct an executable's process tree. These agents operate across your existing SIEM, EDR, cloud, and identity systems without requiring you to centralize or relocate data.
Each agent operates with least-privilege access and returns structured, machine-readable results. The LLM reviews those findings against the original hypothesis, assigns a confidence score, and produces a decision that is evidence-backed, fully transparent, and ready for human review.
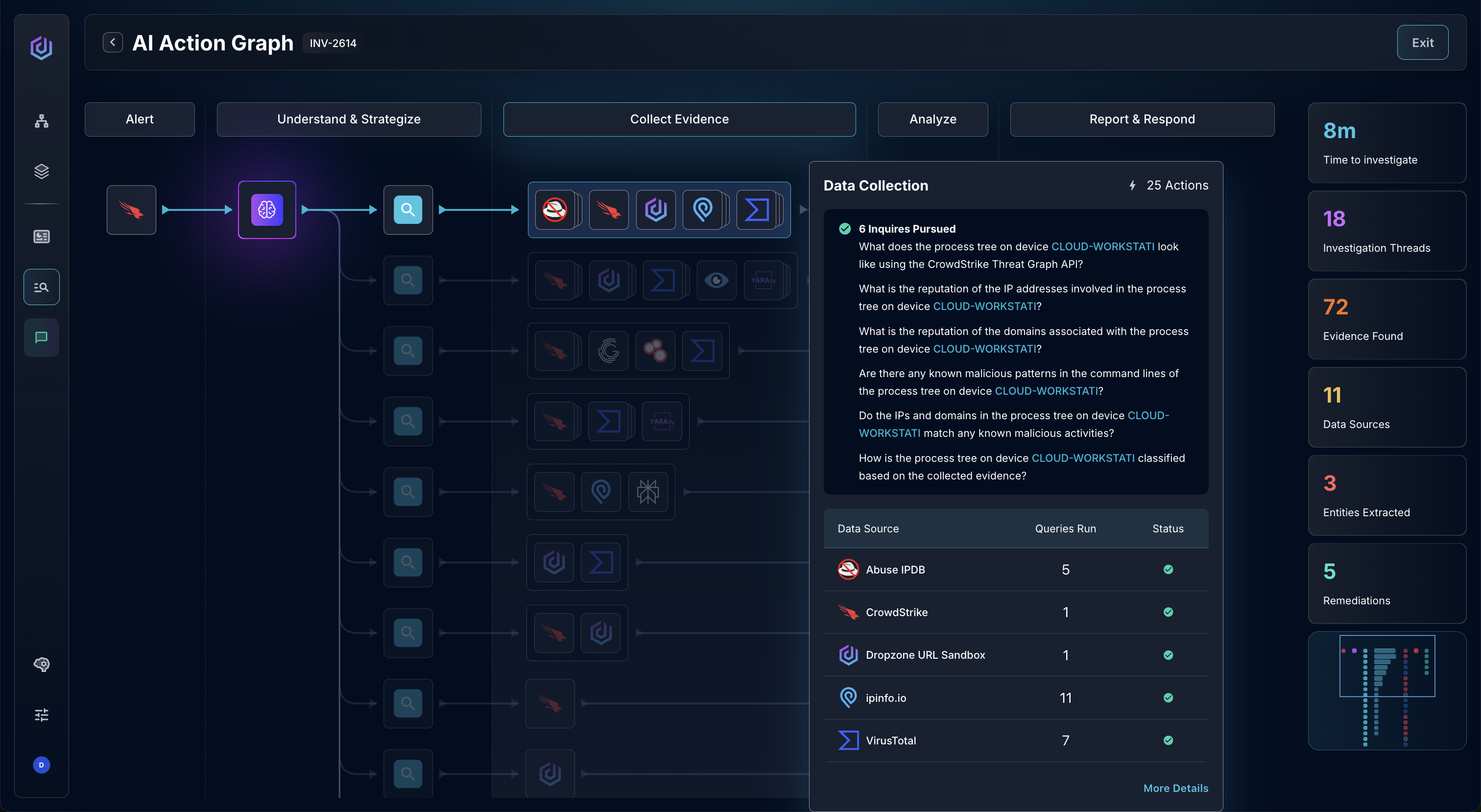
How Do You Keep AI Agent Autonomy Bounded and Accountable?
Bounded autonomy rests on five controls that stay in place regardless of how agents reason:
- Scoped agents. Every agent operates within a clearly defined scope; no single component has unrestricted authority across systems.
- Limited capabilities. Access boundaries are explicit, and capabilities are limited to specific authorized tasks.
- Full investigation logging. Every step is logged, reproducible, and traceable during audits or post-incident reviews.
- Human-defined escalation. Humans own escalation criteria, automation thresholds, and response authority, with override paths always available.
- Quality assurance before and during production. The system can be tested in staging environments before entering production workflows and monitored on an ongoing basis.
Scale comes from repeatable investigation patterns, not from expanding access or authority. The result is autonomous alert investigations running 24/7 at machine scale, lower analyst cognitive load, and controlled automation that expands coverage without expanding headcount.
Conclusion
The shift from chatbots to agents is already underway, and the pressure to grant them more autonomy will only grow. But in enterprise security, unconstrained execution typified by OpenClaw is a serious liability. Systems that can touch data, identities, and infrastructure must operate within clear boundaries. The model that will win is structured autonomy, where flexibility is applied at the judgment layer, and constraints are enforced at the access layer. If you want to see how this looks in practice, explore our self-guided demo and step inside a live AI SOC environment built around controlled, explainable autonomy.